[2000-03-11]
Written by Eddy L O Jansson and Matthew Skala
"Cyber Patrol has sophisticated anti-hacker security." -- Cyber Patrol readme.txt
Several attacks are presented on the "sophisticated anti-hacker security" features of Cyber Patrol® 4, a "censorware" product intended to prevent users from accessing Internet content considered harmful. Motivations, tools, and methods are discussed for reverse engineering in general and reverse engineering of censorware in particular. The encryption of the configuration and data files is reversed, as are the password hash functions. File formats are documented, with commentary. Excerpts from the list of blocked sites are presented and commented upon. A package of source code and binaries implementing the attacks is included.
The market is full of "parental control" applications, and as has been shown in earlier essays [DFR98, DFR99], they are mostly of low technical quality. When we now look at Cyber Patrol (v4.03.005), we find that this trend continues. Some things are a little better than what we're used to from products like CyberSitter and NetNanny, but mostly, things are the same.
We will begin by presenting our goals for the evening, with a small digression on the "how" and "why" in a section we call Metodus operandi, followed by a quick overview of our target for the day. We start getting technical as we do a quick presentation of a cipher found in the target. After that little snack we move on to the main course, something a little bit more complicated, the cryptanalysis of a hash function. At this point we have completed the first goal, and so we move on to take a closer look at how CP manages its URL database. Putting the technicalities behind us we make some observations about the product as a whole. As we take our last bite out of the target, we treat ourselves to a dessert; some source & binaries to drive our point home. All good things must end, so also this pleasant evening. We draw our conclusions, say our goodbyes and part with only a handful of references to follow up on.
Let the festivities begin!
People often ask "How can I learn to do these things?". The answer is the same as for all other things you want to learn: you must study, and you must practice. This, of course, was not the answer the questioner was hoping for. There is a certain amount of "magic" in learning this crude form of reverse engineering. There are no books to learn from, and most of the material on the web is quite bad. There are some excellent essays from some excellent practitioners out there, but while the knowledge possessed by the authors is often great, their presentation is often sub-par, which can make the material inaccessible to the beginner.
There's really no substitute for practice, but what you must have is a firm ground to stand on. This means good knowledge of binary arithmetic and of the platform you are to work with, both the processor and the operating system. While these things can actually be learned by means of books and classes, most people are probably self-taught in these matters.
It's been said that to be good at creating ciphers, you must be good at breaking them. Similarly, we'd like to say that to be good at reverse engineering, you must be a good programmer. So, if you haven't already, learn a language or two.
Now, let's say you have all the background knowledge you need. Then you need some tools. You will need a good debugger. There are a couple out there, but for the Win32 platform most people are using the one included in their development environment, such as the one in Microsoft's Visual Studio, or one of NuMega's offerings, of which the crown jewel is the systems debugger SoftIce. SoftIce has been the tool of choice of crackers and device-driver developers for over half a decade now, and it is a very competent product. In addition to a couple of programming languages and a good debugger, you will want a good hex-editor. Here the choices are plenty, at least on the "WinDos" platform. One good hex-editor which is often mentioned is HIEW. It's a favourite primarily because it supports some disassembly functions and because many of us feel comfortable in the Norton Commander-esque interface. Speaking of disassembly, you will probably want a good disassembler, and here there is really only one product worth mentioning by name, and that is IDA. There're quite a few other disassemblers out there, but IDA - which disassembles ELF executables too by the way - is the most advanced and most competent of them.
In addition to the big three, there are some other utilities that you might want to add to your toolbox. We're thinking mainly of such tools as regmon and filemon by SysInternals.
Add in a little paper, a good pencil and possibly a calculator, and you are all set.
Now, this is not meant as an essay for teaching real beginners about reverse engineering, cryptanalysis or any such matters, but feedback from the essay on NetNanny indicates that the pieces on how the reversal was done were really appreciated by you readers, and so we will try to incorporate some of that into this essay too. Hopefully, those of you not interested in these matters will find it easy skipping the sections in question.
Let's start from the beginning. Before we even install a product we must have some set of goals we want to achieve. For Cyber Patrol the goal was to break the authentication scheme and to extract the URL database, documenting the structures in the progress, thus facilitating interoperability. These constitute practical goals. You will also find less pragmatic goals for the launching of an attack, such as the inquisitive desire to learn the internals of someone else's product, the thrill of doing something you are not supposed to be able to do, and the recognition you might gain for being the first one to explore unchartered territory. We can call these goals of personal gratification. More interesting for the majority of people are probably the political goals, to expose any hidden agenda that might be lurking behind the product and to fuel the discussion around it, in this case the discussion around censorware. For us, the primary motivation has been the possible political implications.
With the goals firmly set in mind, we begin our work to achieve them.
Installation is straightforward. You will note, however, that you are not asked to supply an installation path. This is a typical example of producers taking the easy way out. Rather than going through with the little extra bit of effort, they chose to take the easy route - by forcing all their customers to install the software into C:\PATROL no matter what.
Now, before we speak some more on how we can achieve our goals, let's go on a short tour of the program. For reference, here's a screenshot of the main interface. As can be seen, a large part of the main interface is devoted to time management. For each day in the week you can - with a 30 minute granularity - control the hours in which a user is allowed to use the Internet. You can set the maximum amount of time "online" allowed per day and calendar week.
To the upper right, you'll find a panel for controlling the filters in Cyber Patrol. It's fairly straightforward, but let's run through the alternatives anyway.
Also in the main interface, under "categories" the following categories are available for filtering:
It is, as we will show in the section on file formats and the URL database, not a coincidence that there are sixteen categories in this list. The last four entries, named "reserved", are greyed out and cannot be toggled on or off by the administrator. In addition, "Reserved 4" and "Reserved 3" are selected, and thus cannot be unselected. We'll comment more on this later, but rest assured that an opportunity for foul play lurks right there.
Now, let's review our goals. First, we want to break the authentication, so let's talk about that. There are three levels of access in Cyber Patrol. You could be the administrator, which gives you full access to both the Internet, naturally, and to administering CP. Below the administrator is a "deputy". A deputy is someone who's given full access to the Internet, bypassing CP, but is not allowed to do administration. Everyone else is simply a "user" and must abide by whatever filtering and rules CP enforces.
After installing CP it will install its hooks and remain loaded in the background. To disable it you must authenticate against it. If you want more than one person to have administrative privileges, then you must give them the administrator password; similarly for deputies. As the administrator you can add users, which is simply a matter of assigning a password to go with the username and then setting up the restrictions you want to apply to him or her. A user can then authenticate against CP by right-clicking on the CP icon in the taskbar and select his or her name from a list of all users configured. After you've chosen your username you'll be prompted for the password. It's generally acknowledged that giving out account names like this is bad security since it makes it easier to attack them, for example by guessing likely passwords.
Now, to break the authentication we must simply follow the flow from where we enter our password, to where the valid passwords are retrieved and compared against ours. Or, so goes the theory...
Real life isn't nearly as neat and perfect as our theory would have it. In order to break the authentication scheme, i.e. extract the passwords, we must first locate them. The obvious way, and so our theory says, is to trace the path from entry down to comparison. In the case where retrieval was done earlier and thus is not in the path, we can actually backtrack once we've found out what our password is compared to. We would do that by setting a breakpoint on the memory occupied by the data our password was compared against, then - by restarting the application - gaining access to the point where that data is loaded. This, however, was not the path we took in this reversal. We were a little bit less methodical, but maybe a little bit more intuitive.
We quite simply disassembled the target and browsed it for suspicious code. Using the debugger to locate something like this can be very effective in terms of time spent, but in the grander scheme of things you will want to spend some time browsing the disassembly just to get a feel for the program. The debugger is great for following a specific path and to learn exactly what gets loaded into every register, but it's not a very effective way of learning to know the program more generally, because it's hard to track different code paths with it.
So there we were, browsing our disassembly of CP.EXE for suspicious code. So what constitutes suspicious code, anyway? This of course depends on the context and the type of application, but as a general rule you will want to slow down when you encounter xors used in any other way than with the same register as both source and destination, as in xor eax, eax, or against an immediate value not a power of two. We're looking for clusters of bit-manipulation instructions; shifts, ands, ors, xors, rotations and compact loops. These are all signs that you might be dealing with some sort of encryption routine.
So, lazily browsing the code was how we ended up in a routine we call cp4crypt(), which we will now examine in detail. In reality we're speaking of two different routines, one doing the encryption and one doing decryption. We'll use the term cp4crypt to mean these two collectively, or the cipher algorithm they express.
The first thing one wonders when one finds a suspicious routine is "For what is this routine used?". An important question, and to answer it we use our next most powerful tool, the debugger (the most powerful tool of course being your brain, and don't ever let anyone tell you otherwise). By inserting the special opcode 0xCC, or INT3 as it is also known, into the suspicious code, we can make the debugger active when the routine is run. Typically you will want to enter this into the entry-code of the routine.
To give you an idea of how "suspicious" code can look, here is the piece of code we found:
4D6D:0025 loc_4D6D_25: 4D6D:0025 66 8B CA mov ecx, edx 4D6D:0028 4D6D:0028 loc_4D6D_28: 4D6D:0028 D0 C8 ror al, 1 4D6D:002A 67 32 03 xor al, [ebx] 4D6D:002D 67 88 03 mov [ebx], al 4D6D:0030 66 43 inc ebx 4D6D:0032 67 E2 F3 loopd loc_4D6D_28 4D6D:0035 66 2B DA sub ebx, edx 4D6D:0038 FE CC dec ah 4D6D:003A 75 E9 jnz loc_4D6D_25
The sequence of instructions that start with the ror (rotate right), followed by xor reg,mem (which is really a memory fetch) and then a memory store in mov [ebx],al triggers our interest. We also notice the two tight loops. This is a school book example of Intel x86 encryption/decryption code, similar in complexity to the things you might find in old DOS viruses.
For those of you unfamiliar with the architecture it should be noted that this particular Intel instruction set is read with the destination to the left and the source to the right, so the xor operation fetches the byte addressed by ("pointed to by") the register ebx and xors that byte with the value in the register al, and then stores the result back into al.
The section of code above is a decryption routine. When the whole thing is translated into a higher level pseudo-code it reads something like this:
key = ctsize & 0x000000FF
do twice
{
for each ctbyte in file
{
rotate key right
ptbyte = ctbyte ^ key
key = ptbyte
}
}Algorithm in English:
There are numerous issues with this algorithm which make it very weak. First of all we have the key size, which - weighing in at only eight bits - is, shall we say, very short of being impressive. Of course, since we have the code for deriving the key (that ctsize & 0x000000FF operation) a longer key wouldn't be much use anyway.
Obviously this was never intended to be strong, but even so, someone, some where, spent time developing this scheme. There are certainly simpler ways of doing weak encryption than this, but this is actually a perfect example of the kind of homebrew encryption you are likely to find in commercial applications.
To continue, the key update schedule is weak in that the key only depends on the previous byte. This means that plaintext repetitions longer than the number of rounds used will show through in the ciphertext. The number of rounds used by CP, as described above, is two. A competent cryptographer should be able to break this in mere hours (and by breaking, we mean recovering the plaintext and with it the algorithm), having access only to ciphertext. In real life we also have some assumed plaintext in that the file 'cyberp.ini' is encrypted using this scheme. Such a file probably starts with "[" or ";" and ends with 0x0d,0x0a, to mention but a few hooks. The use of two rounds strengthens the cipher somewhat from a ciphertext only attack, but... this is academia, not really relevant to our real life situation, in which we don't have to recover the algorithm by means of cryptanalysis of ciphertext. We can simply locate and translate the algorithm as it is implemented in the target. Much easier, much faster, though maybe a little bit less fun and rewarding.
We introduced you to the decryption code because it's somewhat simpler to explain compared to the encryption code. The reason for this is that we must, in effect, encrypt the buffer backwards, and we must also treat it as a circular buffer, and even then we need to do a fixup at the end to key the encrypted data. Because of these complications we'll present some code that is a little closer to an actual implementation than pure pseudo-code:
for i = BufferSize-1 downto 1 do
{
key = Buf[i-1]
rotate key right
Buf[i] = Buf[i] ^ key
}Now, the buffer must be seen as circular due to the way the key (which is set to the previously decrypted byte when decrypting) carries over from one round to the next. It's possible to write this into the loop above, but in our case that would only make the explanation more difficult to follow. Anyway, after the loop we connect the two ends of the buffer:
key = Buf[BufferSize-1]
rotate key right
Buf[0] = Buf[0] ^ keyAfter that little tie-in we do another round of the backward encrypting loop above, after which we must do one final fixup for the first byte by keying the whole buffer with the lower eight bits of the buffer's size.
key = BufferSize & 0x000000FF;
rotate key right
Buf[0] = Buf[0] ^ keyThere, now Buf[] will be encrypted. See the section on sources and binaries if you want to look at an actual implementation of these algorithms.
Now, for the question we posed, for what is this encryption used? cp4crypt() is used to encrypt some of Cyber Patrol's data files, such as the file cyberp.ini which contains configuration and user information, and also the administrator and deputy passwords. This cipher also protects the raw URL database, i.e. the files cyber.not and cyber.yes. It is also used on the file user.lst which contains some configuration information, most notably any additional URLs the local administrator(s) may have added.
Let's talk about the passwords. The cyberp.ini contains a main section, "Cyber Patrol", under which the two passwords are stored in the keys "HQ PWD" and "DEPUTY PWD". The data of both these keys is encoded as a hexadecimal string representing eight bytes, or 64 bits if you prefer. It can look something like this:
HQ PWD=3AD6AF0CB33D8A87 DEPUTY PWD=9A3740C7019A5AA1
The deputy password is in fact the password encrypted using cp4crypt(), so it is a simple matter of decoding the hex-string into binary and then decrypting the string using the key 0x08, the maximum length of a password, and voilá; instant unrestricted access to the Internet. Are you impressed? We're impressed.
This file also contains any additional users that have been configured. First the main section contain keys of the form "UserNameNN=name" where NN is a number. Associated with these keys are sections of the form "[UserNN]", which contains not only that users configuration but also his password (in the key "password"), again, encrypted using cp4crypt().
But here things become interesting, because the administrator password is not encrypted in this way, the data for the administrator password is in fact a 64-bit hash value. Analysis of the hash function follows.
Throughout this section we'll use vaguely C-like notation, with some of the extensions common in cryptographic circles. In particular:
All numbers are unsigned, and bits are numbered from 0 (least significant). When we get to the mathematical part, we'd ideally like to use some notation that doesn't map into ASCII. There we'll use reasonable approximations:
Cyber Patrol uses a technique called "hashing" for its HQ password. Instead of simply storing the password in its configuration files, it processes it through a "hash function" to produce a code called a "hash", and it stores the result. The hash function is supposed to have these properties:
These properties guarantee that the program can recognize the correct password when it's typed, but people like ourselves can't determine the password when we reverse engineer the program, even if we obtain the hash. In practice, even a very strong hash function cannot guarantee these properties perfectly - for instance, we could always try all possible passwords until we found the one that gives the correct hash. If the hash is shorter than the input password, then it's absolutely guaranteed that some two inputs will have the same hash. But strong hash functions do exist, which come close enough to the theoretical ideal for most purposes. Cyber Patrol's hash functions are not like that. The deputy password isn't even truly hashed; it is encrypted with the cp4crypt() routine already discussed.
The hash function for the Cyber Patrol HQ password looks like this in pseudocode:
(1) hash1 = 0 (2) hash2 = 0 (3) for every character in the input: (4) input character |= 0x20 (5) hash1 = (hash1>>8) ^ table[(hash1 & 0xFF) ^ (input character)] (6) hash2 = (hash2<<<5) + (input character) - hash1 (7) end for (8) result is hash2 concatenated with hash1 (64-bits)
The first thing we notice here is that every input character gets bit 5 set in line (4). That seems to be case conversion - it forces all alphabetic input characters to lowercase. It has some other effects as well (making certain punctuation characters equivalent to each other) but if the passwords are expected to always be alphanumeric, that shouldn't make much difference. One significant issue (which we'll revisit later) is that it gives attackers a bit of known plaintext: we know that bit 5 of every input character is 1. We can also guess that bit 7 of every input character is 0, since it's tricky to type characters with that bit set to 1 on an ordinary keyboard.
Next let's look at line (5). This one may seem a little confusing: we shift 8 bits out of hash1, look them up in a table (using the input to screw with the index of the table), and XOR the result back into hash1. The table, if you look at it, seems at first glance to be random garbage. Here we just have to depend on our experience to enable us to recognize the code: it happens that this code is a standard idiom for hash calculation.
To be precise, it's a 32-bit linear feedback shift register, also known as a CRC (cyclic redundancy check). This kind of algorithm is a traditional way of checking data integrity in things like file transfers and compressed archive files. Most serious programmers have written it, or something very much like it, before. The definitive explanation of CRCs is in [RNW93]. Most people who have to write CRC code consult that file for instructions; it's a reasonable bet that Microsystems based their code on it. Line (5) of our pseudocode is pretty much verbatim from one of the examples in that document.
The code in Cyber Patrol isn't even just any CRC - examination of the table shows that except for a nonstandard initialization, it is the de facto standard CRC32 algorithm, used in ZModem, PKZip, Ethernet, and FDDI (among other places). CRC32 has proven to be a very successful error detection measure in these systems. Because it provides pretty good bit diffusion (i.e. changing one bit in the input changes lots of bits in the output) CRC32 is also a reasonable hash function just as a hash function. If you were building a hash table data structure, CRC32 wouldn't be a bad way to generate your indices. It is not, however, a cryptographically strong hash function suitable for password hashing. CRC32 has fatal cryptographic holes - it not only provides no security, but also gives us a lot of hints for breaking the rest of the hash. We'll show how to exploit the holes below.
Before we do, let's look at hash2, the other half of the 64-bit hash. This seems to be something homemade, created by throwing together several different techniques in an effort to provide cryptographic strength. That isn't a good way to build cryptographic systems, but in this particular case, it seems to have resulted in something that is at least better than the CRC half of the hash.
There are three basic parts to the hash2 calculation: rotate the previous value, mix in the input character, and mix in the current value of hash1. The rotation gives us a little bit of what cryptographers call avalanche - bit changes get shifted around to eventually affect most of the word. Using addition and subtraction instead of XOR is important because the carry bits allow some information to flow from one bit position to the next.
The designers are treating hash1 as a random number, and hoping to confuse things by mixing it in at every stage. It's not really very random at all, but combined with the carry bits and the rotation, there is a little bit of security here. In fact, in our attacks we haven't bothered to do much to hash2, cryptographically speaking; the results on hash1 are strong enough that we can get away with ignoring most of the holes that may exist in hash2.
We might well speculate about the reasons for designing the hash function this way. It looks like Microsystems chose the CRC32 algorithm because they knew it was a standard algorithm, and then they knew that 32 bits wasn't enough for a cryptographically strong algorithm, so they added some stuff. They knew that bit rotations are popular in cryptographic algorithms, and they knew that addition and XOR are popular, so they put in some of each.
If they knew more than a little about how CRC32 worked, they'd have used a 64-bit CRC instead of extending the 32-bit version with homebrew stuff. If they understood the security implications of CRC32, they wouldn't have used it at all. So the general pattern here is that the pieces are there, but they aren't understood nor put together systematically. If you have a copy of the Jargon File[JRG00], the entry for "cargo cult programming" might be educational.
Now, let's talk about cryptographic strength. Strength of cryptographic algorithms is measured by the order of magnitude of the fastest or most space-consuming attack. An algorithm is strong if the best attack takes too much time or space to be practical; it's also preferable that the best attack be a straightforward brute-force attack, because any other attack indicates a security hole which might easily become worse as the theory of cryptanalysis improves. An attack's difficulty is the amount of time or space it requires, whichever is worse, typically measured as a power of two (like "2**64").
This table is designed to give a very rough idea of the scale of the numbers involved. The exact time to attack a system will depend very much on the system, the optimizations, the hardware, etc. (what computer scientists call "constant factors"); as a result, the stuff in this table could well be off by a factor of a thousand or more in either direction. Where we're going, that isn't going to matter.
| Difficulty | Resources required |
|---|---|
| 2**0 | Pencil and paper |
| 2**8 | Pencil and paper and a lot of patience |
| 2**16 | Warez d00d with a Commodore 64 |
| 2**32 | Amateur with an average PC |
| 2**40 | Smart amateur with a good PC |
| 2**56 | Network of workstations, custom-built hardware |
| 2**64 | Thousands of PCs working together for several years |
| 2**80 | NSA, Microsoft, the Illuminati |
| 2**128 | Cubic kilometers of sci-fi nanotech |
| 2**160 | Dyson spheres |
Some real-life examples: the EFF's "Deep Crack" machine uses custom VLSI to solve a problem of difficulty 2**56 in a few days. The distributed.net RC5 effort is attacking a problem of difficulty 2**64 and expects to finish within a few years. The maximum keyspace of symmetric cryptography exportable without a license from the United States, before they made the rules more complicated recently, was 2**40. Standard practice in most crypto circles is to use symmetric encryption keyspaces of 2**112 or 2**128. Those aren't directly comparable with the cryptographic hash sizes we're talking about, but the point here is the general size of the numbers involved.
There are two ways in which you could break a cryptographic hash function: you could find an input that will produce a specified output, or you could find two inputs that produce the same output. For a hash with n bits of output, assuming it's cryptographically perfect, the difficulty of finding an input for a specified output is 2**n time, negligible space, and to find two different inputs with the same output, 2**(n/2) time and space. So, the two basic attacks we could apply to the HQ password (assuming it was perfect) are:
1. Brute-force search: try inputs until one gives the right output, finds an input for a chosen output in 2**64 time and 2**0 space.
2. Birthday Paradox attack: try inputs, remembering their hashes, until we find two with the same output. Finds such a pair in 2**32 time and space.
The prompting code in Cyber Patrol limits password inputs to 8 characters, and we bash them to lower case and can assume the high bits are zero, so there are in fact only 48 bits of unknown input to the hash. That reduces the time for a brute-force search:
3. Brute-force search with assumptions about input: finds password for a given hash, in 2**48 time, 2**0 space.
That's starting to get into the range where it's feasible to attack. In fact, this attack lends itself to a time/space tradeoff because the hash is unsalted. Let's talk about Unix and salt for a minute. The Unix operating system uses a similar concept of password hashing. It doesn't store the user's password in the password file - only a hash (based on the DES algorithm) of the password. If it were a pure hash of the password, then a determined cracker could compile a codebook of all possible passwords and their hashes, and just look up each hash in the list. Also, the cracker could go down a list of users and recognize who had the same password (because they'd have the same hash) even without knowing what the password was.
To prevent such attacks, Unix has a concept of "salt". Before hashing the password, the system chooses a random number called the salt. It then hashes the salt along with the password, and stores the salt and the resulting hash in the password file. Now a given password can hash to a lot of different values, depending on the salt. The attacker can't compile a codebook, or at least the codebook would have to be a lot bigger, because its size is multiplied by the number of possible salt values. The attacker can't identify pairs of users with the same password, because they'll probably have different salts and so different hashes.
Cyber Patrol doesn't use any salt. As a result, it's vulnerable to a codebook attack, which as you can see is really just a time/space tradeoff of the brute force search above:
4. Codebook attack: 2**48 time and space to compile the codebook once and for all, 2**0 time to look up each password.
All those attacks apply to any hash function with this amount of input and output, no matter how cryptographically strong it may be; to avoid them, Microsystems would have to use a longer, stronger hash function. We like SHA1; it's got a 160-bit output and no known attacks better than brute force, so it takes 2**160 time to attack by brute force search, and 2**80 time and space for the much weaker birthday paradox attack. Of course, the prompting routines in Cyber Patrol would have to be modified to accept longer keys; with 48-bit passwords, about all they could do would be add salt, and pray.
The first cryptographic hole that's apparent in the Cyber Patrol hash is that the per-character processing is bijective, for a given input character. What that means is that if we know the input character and the output, we can be absolutely sure of what the state was before that character. All we have to do is reverse the steps; we won't dwell on how to do that here because we have better things to do, but it's not hard to figure out.
The bijective nature of the hash function makes it possible to do a meet-in-the-middle attack. To find an input for a given output, we hash about 2**32 guesses for the first half and store them. Then we hash backwards from the known output, about 2**32 guesses for the second half of the input. After doing that amount of work we expect to find about one pair of a first half that goes to an intermediate value with a second half that comes from the same intermediate value, and then we've broken the hash. This is about the same amount of work as the classic birthday paradox attack, but it allows us to find an input for a chosen output instead of just two inputs for the same output. It's enough to indicate that the Cyber Patrol hash is a lot weaker than a theoretical perfect cryptographic hash of the same size. But as we'll soon see, we have much stronger attacks on it.
5. Meet-in-the-middle attack: input for a chosen output in 2**32 time and space.
Before we can talk about the difference between CRC32 and cryptographic hash functions, we have to learn some math. Let's talk about modulo arithmetic. Suppose you have an equation involving integers, addition, subtraction, and multiplication, like this:
12 + (34 * 56) = 1916
In modulo arithmetic, we have a number called the modulus, and we say that any two numbers are considered equal (or "congruent") if they have the same remainder when you divide them by the modulus, or in other words, if they differ by exactly a multiple of the modulus. It's an amazing fact that if you take any equation like the one above and replace all the numbers with their remainders when you divide by some modulus, you get a congruence that works. For instance, let's take all the numbers modulo 9; we can do that by adding up all the digits, and then if the result is two digits or more, adding up those, etc. This is the old accountant's trick of checking computations by "casting out nines":
12 + (34 * 56) = 1916 <-- equation 3 + (7 * 2) = 17 = 8 (mod 9) <-- congruence
Note that 17 (or 8, which is the same thing) is what you get if you take the digits in 1916 and add them up. All the numbers in the mod 9 congruence come from adding up the digits in the equation above.
In modulo n arithmetic, there are really only n numbers: 0 up to n-1. Anything else is congruent to one of those. To understand CRC32 we're going to use the second most boring kind of modulo arithmetic: modulo 2. In our mod 2 universe there are only two numbers, 0 and 1. Are you starting to see how this could be relevant? Incidentally, the very most boring kind of modulo arithmetic is mod 1; everything equals zero. Anyway, let's look at the addition and multiplication tables for modulo 2:
| + | 0 | 1 | * | 0 | 1 | |
|---|---|---|---|---|---|---|
| 0 | 0 | 1 | 0 | 0 | 0 | |
| 1 | 1 | 0 | 1 | 0 | 1 |
Notice anything? The addition table is the same thing as what we like to call ^ (XOR) and the multiplication table is the same thing as what we like to call & (AND). This connection is important because it means we can take programs which do bit twiddling, and apply the mathematics of addition and multiplication to figure out what's going on.
The CRC32 algorithm simulates a linear feedback shift register. We won't try to draw the diagram here, but the concept it simple: you shift bits out of the register one at a time, and you have a mask that's as long as the register, and you XOR the stream of bits you shift out with the stream of input bits, and every time the result is 1, you XOR the mask into the register. Why this is useful is best explained in [RNW93]; we'll just take it for granted that in communications error checking, this is a sensible thing to do. The 8-bit shift, and the magic table, are just a clever way of doing a whole byte at once. The result is the same as if you did the bits one at a time.
What's important cryptographically is that after you've performed one cycle, every bit is either equal to the bit next to it (if its mask position was 0), or it's equal to the XOR of the bit next to it, the bit that just got shifted out, and the input bit (if its mask position was 1). Let's say we have a short register, four bits long, with the mask value 1011. Let a[0] to a[3] be the previous state, b[0] through b[3] be the next state, and x be the input bit. Then we have:
b[3] = x + a[0] (mod 2) b[2] = a[3] (mod 2) b[1] = x + a[0] + a[2] (mod 2) b[0] = x + a[0] + a[1] (mod 2)
Notice how we're using the + symbol to denote bit XOR; in modulo 2, it's the same thing. The most important thing to notice here is that every output bit is a XOR of some combination of the input bits. If you take two output bits and XOR them together, you find that the result is still simply a XOR of some of the input bits:
b[1] = x + a[0] + a[2] (mod 2)
b[0] = x + a[0] + a[1] (mod 2)
b[1] + b[0] = x + x + a[0] + a[0] + a[1] + a[2] (mod 2)
= a[1] + a[2] (mod 2)
Note that we can get rid of all the terms that are repeated twice or an even number of times, because those are like multiplied by an even number, and all even numbers are equal to zero in modulo 2 arithmetic. OK, it takes some getting used to, but it really is easy once you see it.
With the CRC32 algorithm, there are lots more variables than in that example, but this same general property holds: the CRC32 bits are each the modulo 2 sum of some combination of the input bits. Actually, in strictly correct CRC32 it's a little more complicated because the register doesn't start at 0, so you have to XOR in some extra bits that depend on the length of the input. But fortunately for our discussion, Cyber Patrol uses a nonstandard variant of CRC32 which initializes the register to 0.
We can figure out a congruence for each output bit by feeding inputs into CRC32 which consist of only one bit set to 1 and all other bits set to 0. If an output bit is set for that input, then the input bit that was 1 is included in the congruence for that output bit. Once we've tested all the input bits this way, we have the entire congruences.
To save space on the page, we will write out our congruences with all the variables included, multiplied by 0 or 1, like this:
0*b[0]+0*b[1]+0*b[2]+1*b[3] = 1*x+1*a[0]+0*a[1]+0*a[2]+0*a[3] (mod 2) 0*b[0]+0*b[1]+1*b[2]+0*b[3] = 0*x+0*a[0]+0*a[1]+0*a[2]+1*a[3] (mod 2) 0*b[0]+1*b[1]+0*b[2]+0*b[3] = 1*x+1*a[0]+0*a[1]+1*a[2]+0*a[3] (mod 2) 1*b[0]+0*b[1]+0*b[2]+0*b[3] = 1*x+1*a[0]+1*a[1]+0*a[2]+0*a[3] (mod 2)
and then leave out everything except the coefficients (the 0 or 1 we multiply by):
000111000 001000001 010011010 100011100
That block of bits has all the information from the complete set of congruences. It's what mathematicians call a "matrix", but there's no need to think too hard about what that means; just call it an abbreviated set of congruences. Each row is equivalent to a congruence, and we can add congruences to each other (the same way we did earlier) by XORing one row into another. If we shuffle the rows around and XOR them enough, we can solve for whatever variables we want - it's just like the simultaneous equations we learned in high school. For example, if we desperately want to know the value of a[1] in the example, we can say:
b[3] = x + a[0] (mod 2) b[0] = x + a[0] + a[1] (mod 2) b[0] + b[3] = a[1] (mod 2)
or in our abbreviated notation:
000111000 + 100011100 = 100100100
We wrote code to figure out the set of congruences for the CRC32 algorithm as implemented in Cyber Patrol, using all 32 output bits and 96 input bits (12 characters, which is overkill, but bits are cheap). Here's the resulting matrix. Input bits come first, first bits 0 to 7 of the last byte, then bits 0 to 7 of the second-to-last byte, and so on; after that are the 32 outputs, again in order from 0 to 31. (This ordering of bits was easiest to program; it doesn't really matter.)
00100000100010111000000011111011000100101101100001110010010110101000111101000001010111111110000010000000000000000000000000000000 10010000010001011100000001111101000010010110110000111001101011011100011110100000001011111111000001000000000000000000000000000000 11001000001000101110000010111110000001001011011010011100110101100110001111010000000101111111100000100000000000000000000000000000 01100100000100010111000001011111000000100101101101001110111010110011000111101000000010111111110000010000000000000000000000000000 10110010000010001011100000101111100000010010110110100111111101010001100011110100000001010111111000001000000000000000000000000000 01011001000001001101110010010111110000001001011011010011011110100000110011111010000000101011111100000100000000000000000000000000 00001100100010010110111010110000011100100001001100011011011001111000100100111100110111101011111100000010000000000000000000000000 10000110010001000011011101011000101110011000100110001101101100110100010000011110111011110101111100000001000000000000000000000000 01000011101000100001101110101100110111001100010011000110010110010010001010001111111101110010111100000000100000000000000000000000 00000001010110101000110110101101011111001011101010010001011101100001111010000110101001000111011100000000010000000000000000000000 00100000001001100100011010101101001011000000010100111010011000011000000000000010100011011101101100000000001000000000000000000000 00010000000100111010001101010110100101100000001010011101001100000100000010000001110001101110110100000000000100000000000000000000 10001000100010010101000100101011010010111000000101001110000110001010000001000000111000110111011000000000000010000000000000000000 11000100110001001010100010010101101001010100000000100111000011000101000010100000011100010011101100000000000001000000000000000000 01100010011000101101010011001010010100101010000000010011000001100010100011010000101110001001110100000000000000100000000000000000 00110001001100010110101001100101001010011101000000001001000000110001010001101000110111000100111000000000000000010000000000000000 10111000100100110011010101001001000001100011000011110110010110111000010101110101001100011100011100000000000000001000000000000000 11011100110010011001101000100100000000110001100011111011101011011100001010111010100110000110001100000000000000000100000000000000 11101110011001000100110110010010000000011000110011111101010101100110000101011101110011001011000100000000000000000010000000000000 01110111101100100010011011001001000000001100011001111110101010111011000000101110111001100101100000000000000000000001000000000000 00011011110100100001001110011111000100101011101111001101000011111101011101010110001011000100110000000000000000000000100000000000 00101101011000100000100110110100100110110000010110010100110111011110010001101010010010011100011000000000000000000000010000000000 00110110001110101000010000100001110111111101101010111000001101001111110111110100011110110000001100000000000000000000001000000000 00011011000111011100001010010000011011110110110101011100100110100111111011111010101111011000000100000000000000000000000100000000 10101101100001011110000100110011101001011110111001011100000101111011000010111100100000011010000000000000000000000000000010000000 11110110010010010111000001100010010000001010111111011100010100011101011110011111000111111011000000000000000000000000000001000000 11111011001001000011100000110001101000000101011111101110101010001110101111001111000011110101100000000000000000000000000000100000 01011101100110010001110011100011110000101111001100000101100011100111101010100110010110001100110000000000000000000000000000010000 10001110110001110000111010001010111100110010000101110000000111011011001000010010011100111000011000000000000000000000000000001000 11000111011000110000011111000101111110010001000010111000000011100101100110001001001110010100001100000000000000000000000000000100 11000011001110100000001100011001011011101101000000101110110111010010001110000101110000110100000100000000000000000000000000000010 01000001000101100000000111110111001001011011000011100101101101000001111010000011101111101100000000000000000000000000000000000001
Notice the diagonal stripe at the right-hand side of the matrix. That stripe reflects the fact that we have one congruence for each output bit, in order. Now, by flipping and XORing rows (the exact technique we used is called Gauss-Jordan elimination, which is just a formalization of the "system of equations" technique you do in high school) we shuffled that stripe over to the left, to get a set of congruences that tells us the last bits of the input based on the output and the other input bits:
10000100000001000000010000000001000001010000010001110000100011111101101100110010110110100111101101100110001011010100100100001101 01000100000000000000000100000000000000000001101100011101110000101001000001101111011011010101110011111110010010010000110001000100 00100000000001000000000000000101000010010000011011011010010010100100001001001101001001001011110010000011100000011111001100111000 00010000000000010000010000000001000001000000010001000001101111101011000101010111111100111010101111000111010000000101010010010110 00001000000000010000010000000100000010000001101010111000000110001111100110011010110110001111000111111110001010111001010001010001 00000111000001000000000100000100000000000001100010111010011011011100000000110011001111011100001110111010000000100100100011001111 00000101100001000000010000000101000010000000000001111001100101011001110111001010010001101111100111101010100000111011101000010011 00000001010000000000010000000100000000000001111111101111110100010100001101111110111010100110111111010001100000000111101001001000 00000000001000000000000100000101000000000001010111001100001110000101000101000011101010101001110001011101110111000011100111000111 00000000000100000000010100000001000001000000001111010011011000010011010111011111110111010001011101100010001100101001101100100110 00000001000011000000010100000001000001000001011111101110011101001001100100010111000111111101101010110011000110000110111100101010 00000001000000110000000100000100000001000000010011110001101101000111110001000001110110110110001101100100100011011111110101010111 00000101000000001000010000000000000000010001001110110101000010111010010100100100101111001110111111011100011101100111100110000111 00000001000001000100000100000100000001010001101100110011000111000010101101001001001110100110011011011111010111100101100100110101 00000001000000000010000100000100000010010000010111110001101010001110000011110011000001011010110000011011000110110000101111100000 00000001000000000001000000000100000010000000000101111110001101100111001100100100101010111111111011110101010100011001000111111111 00000000000001000000110100000100000010010001101001000110111110001001110010000010001001111011000010000000100000011000110010101110 00000000000001010000001000000100000011010001100111000011011110010110011001011110000010000011101111110000001101011010100011001001 00000100000000010000010110000000000010010000000010000111010111100000100000110101101110001100000111010111011101100000001000110110 00000000000000010000000001000001000011010001110000110101101101011101111110001000111010001000010001000101010101001111100001001110 00000100000001010000000100100000000010000000111101000110001110100010000000011110111001011001110010011000011000100110100011000010 00000101000000000000000100010101000011000001010111110111110001111000111000110100010001001001101110001101001101000001110101011010 00000100000001000000000000001100000000010000110101101010110010010010001110101110010110000101110011100111101000011110011111111110 00000000000000010000010000000111000011000001000011101111011110101100000100100001001111100011100011101001000011010010101111101100 00000000000001010000000100000001100000010000101010010110000110010110010000110001010011001111011110010011001001000110111110111101 00000001000000000000000000000000010000010001011000000001111101110010010110110000111001011011010010101010101100010100001000100110 00000100000000000000000100000101001010010001001010000110011011111010100111011111111011111100010000111101001011100100101101011110 00000001000000000000000000000100000110000001001011011101011000001110010100100110001101101100111010101100000110111000011100101110 00000001000000010000000000000100000000110000111100011111111100001000101001001011011010100101010011101000111001011100111000100010 00000000000000010000010000000101000000001001100110000001110010101011001100110010001001010101111100111111000000001110100001111011 00000001000001000000000100000100000001000100000110111110101100010101011111110011101010110001000000010000110001110100000001010100 00000101000000000000000000000001000000000011000100110001011010100110010100101001110100000000100110010100101000010110110100011101
The diagonal isn't perfect here for a couple of reasons. One, we didn't solve for bits 5 and 7 of any input byte, because we don't have a choice for the values of those bits. We can't allow the congruences to force impossible values on them. Two, we found that some pairs of input bits are actually equivalent to each other. There's no way to solve for both of such a pair - you just have to choose a value for one or the other of them. But the point is that from this "solved" or "inverted" matrix, we have a set of congruences where we can choose all but 32 bits (including all the output bits of the CRC) and then just by evaluating the congruences, we get the values for the other input bits to make the whole thing work.
This is why CRC32 is not a cryptographic algorithm: anyone who knows a little matrix algebra can generate inputs for a chosen output in minimal time. We extracted the columns from our solved matrix and put them into tables in cph1_rev.c. The reverse_crc() function takes parameters specifying the input length, some choices for the "free" input bits, and the desired output value. Then it fills in the "forced" bits for the chosen input length, and goes through its tables XORing together all the columns that correspond to 1 bits in the partial input. Then the result contains all the values for the rest of the input bits. It unpacks them and returns the completed input. The bit packing order is also in tables. Some checking of the result may be necessary because if you ask for a very short CRC input, there may well be no such input for the output you requested.
Now we can attack the Cyber Patrol hash just as if it were a strong hash with only 32 bits of output:
6. CRC-breaking Birthday Paradox attack: choose an output for the CRC32, generate inputs with that CRC32 value, save their hash values, until you have two the same. Finds such a pair in 2**16 time and space.
7. CRC-breaking brute force: choose an output for the CRC32, generate inputs with that CRC32 value until you find one with the hash you want. Finds an input for a chosen output in 2**32 time and 2**0 space.
But because we know that the input password is only 8 ASCII characters, bashed into lowercase by the OR with 0x20, we can improve the attack still further. With 8 input characters there are 48 bits unknown, and of those, we can derive 32 from the set of congruences. That leaves us only 16 bits unknown. We can simply test all possible values for those 16 bits, by brute force. This is the attack implemented by cph1_rev.c.
8. CRC-breaking brute force, with assumptions about the input: finds input for a chosen output (assuming it really came from an 8-character ASCII password) in 2**16 time, 2**0 space. Shorter passwords take much less time, so we can test all shorter passwords first, without increasing the cost noticeably.
Our code for this attack isn't particularly optimized, and we haven't attacked the rotate-and-add part of the hash at all, but even so we can now reverse the function in a fraction of a second. At this point it's appropriate to categorize the Cyber Patrol HQ password hash function as blown wide open, thus fulfilling our first goal.
The primary function of Cyber Patrol is to do filtering based on a database of URLs that are not allowed. CP can also be configured to work with the inverse policy, denying everything but a small set of allowed URLs, a very strict policy.
The source of the URLs that are denied is a file called cyber.not. Conversely, the file cyber.yes is used for the "allowed" URLs. Currently the not file is about 600Kb, with the yes file only about 50Kb. Roughly, this means there are less than one tenth as many allowed URLs as there are denied ones. These files are actually processed into another format and file called cyber.bin for use by the different Cyber Patrol modules. We will not discuss the format of this file since the raw files are much more suited to our needs.
Before we broke the encryption on the cyber.not file, we did some short-range correlation measurements on it, to check for polyalphabetic encryption (like the classic "simple XOR" algorithm). The idea here was to measure, for various values of k, how often the byte at offset x was identical to the byte at offset x+k. We used a simple Perl script to compile these statistics.
We found that very often, after some byte value would occur, the same byte was repeated again six bytes (or, somewhat less often, seven bytes) later. That would point towards some kind of modified polyalphabetic cipher with a key length that switched between six and seven bytes, or some very weak cipher that didn't conceal repeats in the plaintext, and record sizes of six and seven bytes in the plaintext. It turned out to be the latter, but we didn't find that out by cryptanalysis. Reverse engineering yielded the answers more easily, as described earlier.
However, those six- and seven-byte repeats seemed interesting, especially once we had decrypted cyber.not, reversed its header format, and split it out into its component tables. The first table we figured out was the last one in the file, the table of blocked newsgroups.
When reversing a file format it makes sense to start at the easy end, and with the cyber.not file that means the table used for newsgroup masks. What made this the obvious starting location is that it's very obvious - from a fast ocular inspection - what it is for. A section might look something like this (some unprintable characters replaced by question marks):
00065A90: 00 41 00 02-00 00 00 07-02 00 68 38-0B F7 07 11 A ? ?? h8?�?? 00065AA0: 00 FA BD 29-B8 00 5F 0A-28 07 1E 00-45 44 53 44 ��)� _ (?? EDSD 00065AB0: 22 00 04 43-6F 70 79 72-69 67 68 74-2E 4D 69 63 " ?Copyright.Mic 00065AC0: 72 6F 73 79-73 74 65 6D-73 2E 53 6F-66 74 77 61 rosystems.Softwa 00065AD0: 72 65 0D 60-00 61 2E 62-73 75 2E 72-65 6C 2A 0B re ` a.bsu.rel*? 00065AE0: 06 00 61 62-74 2E 6D 61-6D 2A 0B 0E-00 61 62 67 ? abt.mam*?? abg 00065AF0: 2E 74 65 73-2A 0E 0E 00-61 63 61 64-69 61 2E 62 .tes*?? acadia.b 00065B00: 75 6C 2A 07-00 08 61 6C-63 2A 0C 08-04 61 6C 74 ul*? ?alc*???alt 00065B10: 2E 32 33 69-73 2A 0A 09-04 61 6C 74-2E 32 36 2A .23is* ?alt.26*
Some quick looking around would show that "ED" marks "End-of-Data" and consequently "SD" ought to mark "Start-of-Data". The first thing to do is try and see what constrains a record. Either there's a length count, a special marker, or the records are fixed length. They are not fixed length, that much is apparent, but they all end in an asterisk, so maybe that is a record terminator? Could be, but the first string, the "Copyright..." ends with 0x0d. To make sure, we must see if we can find a length marker, a common way to handle variable sized records, and also the preferred method in many ways. Now, because there are three "non-character" bytes between SD and the first string, we try this pattern on the other strings, and it checks out. Thus, we can guess that a record starts with three bytes, followed by a variable number of characters. A way to verify this result is to look at the end of the table, to see what kind of data ends the last record.
Now, for the length, that would have to be one of the three bytes, so it shouldn't be too hard to locate, if indeed it exists. The first record starts '22 00 04' and then the string. The length of the string is more than zero or four, and definitely less than 1024 (0x400). By counting we see that the string is 31 characters, or 0x1F in hex. Very close to 0x22, and where could the difference come from? But of course, the three prefix bytes.
This leaves one or two bytes per record unaccounted for. How many depend on how large the length specifier is. Looking around we find examples of records in which the second byte of the records is something besides zero, which would make the length way too long, and thus we can conclude that we are working with a length byte and not a word. Now them, what about the remaining two unaccounted bytes? As you may remember from the overview we mentioned that there are sixteen different categories available for filtering. The two remaining bytes are actually a blocking mask - a word whose bits maps to those sixteen categories. We call these records TNotNewsEntries.
Having found the start and end, and thereby the size, of one table mean we have some usable information for reversing the next-easiest part of the file, the header. Our header looks like this in binary:
00000000: FC 00 2A 00-43 48 00 00-00 00 03 01-03 00 49 00 � * CH ??? I 00000010: F8 34 00 00-B6 25 06 00-41 00 2C 00-00 00 CC 34 �4 �%? A , �4 00000020: 00 00 4E 00-AE 5A 06 00-B8 25 00 00-53 44 80 53 N �Z? �% SD�S 00000030: 28 0F 02 80-53 28 10 80-53 28 11 D1-01 1C DE 01 (�?�S(?�S(?�??�?
Seeing how "SD" marks the start of data, we can calculate the size of the header as 0x2C bytes, meaning the first table (of which there are at least two, one being the table for newsgroup masks) ought to start at 0x2C, the location of the "SD" marker. Experience tells us that headers often contains pointers (offsets), lengths, and counts (of records). Let's see if we can match any of those types into the header.
We begin to look for pointers into the different tables. We know that the first one start at 0x2C (the "SD" marker, remember?) and it just so happens that we have two viable candidates, first one at offset 0x02 and one at 0x1A. The first one is off by two, so it's a little less likely to be the one we want. Too little to go on, but we also know where the newsgroup table starts: 0x65AAE. Wouldn't you know, there it is at offset 0x24 of the header. Now, let's see if we can find any lengths in there. We begin by measuring the size of the newsgroup table. It runs from 0x65AAE to the end of the file at 0x68065. Subtract and you get 0x25B8, and there it is in the header, following the offset. We can then verify our findings by checking them against the record of the table starting at 0x2C.
Now we have a little more to work with, so we try and determine the size and the location of the first of the headers table-records. We know that one of the table entries end at 0x23 at the latest, because that is where we have our offset to the newsgroups table. We can also be sure that offsets 0x1E through 0x21 belong to the other table, because those bytes contain the length of the first table (whose contents are so far unknown). That leaves only two bytes between them. Implicit in this is a limit to the size of a record, because we know that the newsgroup entry ends at 0x2B at the latest, so it can run from 0x22 through 0x2B ( ten bytes) or 0x24 though 0x2B (eight bytes). And therein lies the answer to the question of the record's length, because we can see that the newsgroup record ends with the length field, and for that to hold the other record should too, which would orphan the two bytes between them. In this way we can come to know that a record is in fact ten bytes, consisting of two bytes (meaning unknown), a longword (table offset) and a longword (table length). Working backwards we can fill out the entries as this:
0x004E, 0x0065AAE, 0x000025B8 0x0041, 0x000002C, 0x000034CC 0x0049, 0x00034F8, 0x000625B6
If we were to go another step back we would get a record like this:
0x4348, 0x0000000, 0x00030103
This clashes with the structure as we know it, and so we assume that there are only three records, the data before them having some other structure. Looking, again backwards, we notice that the word following the first table entry is 0x0003, which could mean that it's a count of the number of tables, right? By checking against another file with the same structure, the hotlist.not, we could see that this assumption was correct.
The little bit left of the header is not as important as locating the table entries and their count, but it seems like the 0x2A at offset 0x02 is the header size, assuming the header starts at 0x02 and the two bytes in front of it being not related to it. The "CH" seems to be a marker, the hotlist.not contains "HH" instead. Without more files to compare to, or time-consuming debugging of the executable, the few bytes left unaccounted for will remain a "mystery".
We learned several important things from the newsgroups list. First, Microsystems likes putting length bytes on things. Second, the blocking mask 0x000E (corresponding to "Partial Nudity", "Full Nudity", and "Sexual Acts / Text") is the most popular one. It appears that that's the generic "porn" label which they slap on everything that looks like it might be porn, whether it technically applies or not. Both these facts were useful in attacking the other two tables in cyber.not.
The first table mentioned in the header is the biggest one. At over half a megabyte, it makes up most of the bulk of the cyber.not file. As our previous measurements indicated, this table includes a lot of repeats at a distance of six or seven bytes. Character frequency counts revealed that the top three characters in table 1 are:
We know that they like using blocking mask 0x000E, and the bytes making up that number are the top two most frequent bytes in the table. We know they like length bytes, we know there's some kind of structure in here with a size of seven bytes, and 0x07 is the third most frequent byte value. This looks promising. Let's look at a hex dump. This dump was generated with the Linux od -Ax -txC command; offsets are from the start of table 1 as specified in the cyber.not header.
000000 53 44 0a 00 03 c7 00 00 07 0e 00 99 37 55 67 00 000010 0a 0a 0a 0a 0e 0c 0b 67 73 76 00 00 07 0e 00 51 000020 b1 f1 6d 00 0c 0a 79 c8 0e 00 0c 0a 9e 09 00 00 000030 0b 01 00 89 84 e0 4e 55 9e 53 d8 00 0c 0a bd 05 000040 00 00 07 0e 00 71 aa 8a 2a 00 0c 0b b8 18 00 00 000050 0b 08 00 ea 1e da d8 d4 fc d4 20 00 0c 0b b8 1a 000060 00 00 07 00 04 e0 3d c1 be 07 08 00 7b 75 fd b7 000070 07 00 04 87 0b 1e ef 00 0c 0b b8 1f 0e 00 0c 0b 000080 b8 2b 08 00 0c 0b b8 2c 0e 00 0c 0b b8 36 08 00 000090 0c 0d 78 02 00 00 07 0e 00 13 53 03 e2 00 0c 0d 0000a0 79 06 00 04 0c 0d ab 97 00 00 07 06 00 31 75 fc 0000b0 80 00 0c 0d 13 5a 0e 00 0c 0e c7 33 0e 00 0c 0e 0000c0 c8 02 00 00 07 0e 00 22 39 82 eb 00 0c 0e e1 0d 0000d0 00 00 07 01 00 0d b0 59 21 00 0c 0e e8 32 00 00 0000e0 07 20 00 7c d3 df f8 00 0c 0f 87 cd 00 00 07 0e 0000f0 00 88 35 ae 33 00 0c 0f c1 72 0e 00 0c 10 a0 d8
This may appear quite formidable to someone unaccustomed to reading hex dumps, but careful examination reveals some interesting things. First of all, the sequence "0e 00" occurs quite frequently. It's reasonable to suppose that that might be the blocking mask for a page or site. Another common one is "07 0e 00". When that one occurs, there are often four more bytes and then those three again. These patterns are easier to see when one examines more of the dump than the short sample here.
It's reasonable to guess that the 07 is a length byte, just like in the newsgroup list. But that doesn't explain why we get so many repeats at distance six. The byte value 0x06 is only the 39th most common value in table 1, even though there are far more repeats at distance six than seven. So not everything can be tagged with a length byte, or there's something else we don't understand.
Further skimming of the hex dump revealed inspirational passages like this one:
037b50 5c b7 08 6f 00 cf cc ae 13 0e 00 cf cc ae c8 0e 037b60 00 cf cc ae c9 0e 00 cf cc ae ca 0e 00 cf cc ae 037b70 cc 0e 00 cf cc ae cd 0e 00 cf cc ae d0 0e 00 cf 037b80 cc ae 15 0e 00 cf cc ae d8 0e 00 cf cc ae 16 0e 037b90 00 cf cc ae 18 0e 00 cf cc ae 1b 0e 00 cf cc ae 037ba0 1d 0e 00 cf cc ae 1e 0e 00 cf cc ae 1f 0e 00 cf 037bb0 cc ae 21 1e 00 cf cc ae 23 0e 00 cf cc ae 24 0e 037bc0 00 cf cc ae 27 0e 00 cf cc ae 28 0e 00 cf cc ae 037bd0 30 0e 00 cf cc 13 ea 0e 00 cf cc c4 c4 0e 00 cf 037be0 cc d0 a0 0e 00 cf cc d0 f8 0e 00 cf cc d2 64 1f 037bf0 00 cf cc d2 a0 00 00 07 0e 00 e5 b0 e3 10 00 cf 037c00 cc d2 18 0e 00 cf cc d2 19 0e 00 cf cc d2 1e 0e
The pattern may be clearer if we look at the bytes six at a time:
037b54 00 cf cc ae 13 0e 037b5a 00 cf cc ae c8 0e 037b60 00 cf cc ae c9 0e 037b66 00 cf cc ae ca 0e 037b6c 00 cf cc ae cc 0e 037b72 00 cf cc ae cd 0e 037b78 00 cf cc ae d0 0e 037b7e 00 cf cc ae 15 0e 037b84 00 cf cc ae d8 0e 037b8a 00 cf cc ae 16 0e 037b90 00 cf cc ae 18 0e 037b96 00 cf cc ae 1b 0e 037b9c 00 cf cc ae 1d 0e 037ba2 00 cf cc ae 1e 0e 037ba8 00 cf cc ae 1f 0e 037bae 00 cf cc ae 21 1e 037bb4 00 cf cc ae 23 0e 037bba 00 cf cc ae 24 0e 037bc0 00 cf cc ae 27 0e 037bc6 00 cf cc ae 28 0e 037bcc 00 cf cc ae 30 0e
Here we've obviously got our generic porn mask of 0x000E, alternating with four unknown bytes, the last of which often seems to be incrementing - but not always. Scanning across the table, we saw that when this kind of six-byte structure occurred, the four mystery bytes seemed to more or less increment smoothly from the start of the table to the end. But it was always the last byte that incremented first, and then the second-to-last, and so on. In other words, the field is being stored in "big endian" byte order, the exact opposite of the "little endian" byte order conventional on PCs. Why would a PC software package bother doing something in big endian when it's running on a CPU designed for little endian?
At this point we had to depend on intuition. There is one thing that's 32 bits long and big endian everywhere, even on a PC: that is an IP address. Some computers like big endian and some like little endian, but it is standard for all Internet protocols to use big endian regardless of what kind of system they're running on - so that they'll all be able to talk to each other. An added bit of evidence is that the actual values of this four-byte field seem to be distributed the way one would expect IP addresses to be distributed. Lots of them start with bytes like 0xCF, which puts them right in the popular part of the Class C IP address space. So, let's write the decimal equivalents of the supposed IP addresses next to the hex dump:
037b54 00 cf cc ae 13 0e 207.204.174.19 037b5a 00 cf cc ae c8 0e 207.204.174.200 037b60 00 cf cc ae c9 0e 207.204.174.201 037b66 00 cf cc ae ca 0e 207.204.174.202 037b6c 00 cf cc ae cc 0e 207.204.174.204 037b72 00 cf cc ae cd 0e 207.204.174.205 037b78 00 cf cc ae d0 0e 207.204.174.208 037b7e 00 cf cc ae 15 0e 207.204.174.21 037b84 00 cf cc ae d8 0e 207.204.174.216 037b8a 00 cf cc ae 16 0e 207.204.174.22 037b90 00 cf cc ae 18 0e 207.204.174.24 037b96 00 cf cc ae 1b 0e 207.204.174.27 037b9c 00 cf cc ae 1d 0e 207.204.174.29 037ba2 00 cf cc ae 1e 0e 207.204.174.30 037ba8 00 cf cc ae 1f 0e 207.204.174.31 037bae 00 cf cc ae 21 1e 207.204.174.33 037bb4 00 cf cc ae 23 0e 207.204.174.35 037bba 00 cf cc ae 24 0e 207.204.174.36 037bc0 00 cf cc ae 27 0e 207.204.174.39 037bc6 00 cf cc ae 28 0e 207.204.174.40 037bcc 00 cf cc ae 30 0e 207.204.174.42
Notice that these are not in numerical order; 216 is not normally considered to come between 21 and 22. However, considered as decimal representations, these addresses are in strict alphabetical order. This list is the kind of thing you might get if you took a text list of URLs and passed it through a sort utility designed for text. A little examination reveals that these six-byte structures in table 1 are strictly in this "text IP" order across the entire table. As a final confirmation that these numbers are intended to represent IP addresses, just point a Web browser to a few. Almost all are porn sites.
At this point we had figured out that there were a lot of blocking masks interspersed with IP addresses in the table, and also a lot of seven-byte structures starting with a length byte and a blocking mask. But the remaining four bytes of those seven-byte structures were apparently not sorted, nor IP addresses, and there were still some bytes that didn't fit into either kind of structure. So we wrote a Perl program to dump out the known structures and label the unknown parts.
The next step was simply to stare at the output and look for patterns. We saw that the six-byte and seven-byte records often occurred in blocks of lots of the same kind all together. The unknown part often seemed to consist of the byte 0x0B followed by a blocking mask and eight bytes of garbage. We guessed that that might be a third record type, so we added it to the dumper program, and noticed that the remaining unknown sequences often seemed to consist of 0x0F, a blocking mask, and then twelve bytes of garbage. From this we inferred a general pattern: a length byte (always 3 plus a multiple of 4), a blocking mask, and then some amount of garbage, always a multiple of four bytes.
Between this and the six-byte IP/mask pattern, almost all the contents of table 1 fit some kind of structure. But there were still a bunch of zero bytes hanging around. A reasonable guess was that these signalled some kind of "end of structure" condition. It only took a little more intuition to realise that of the "length byte" records and the "IP address" records, one logically went inside the other. Unfortunately, we guessed that the "IP address" records went inside the "length byte" records, and that confused us for quite a while. Here's part of the output from our dumping program at this stage:
07 0E 00 0F 25 6B BF 07 0E 00 C8 87 B1 C1 (0501)(0800)(0800)(0000) 0B 02 00 B9 53 9A 71 6A BE 88 54 0B 00 08 B9 53 9A 71 3D 5F E2 F4 0B 00 08 B9 53 9A 71 38 16 1A 41 0B 08 00 B9 53 9A 71 07 B3 CA 02 (000E)(0000) 07 08 00 2F 31 2A 45 (000E)(000E)(0000) 07 0E 00 37 71 0F 71 (000E)(000E)(0008)(0000) 0B 01 00 88 B4 92 0E A6 53 2E 7F (000E)(0000) 07 98 04 08 B0 DD FB 07 08 00 0F E8 F5 82 (0000) 07 09 00 4F DE 86 ED (0000) 07 0E 00 79 1F 36 41 07 0E 00 63 C8 51 C4 (0000) 07 02 00 0A E2 34 93 (000E)(0000) 07 08 00 31 2D E5 BA (000A)(000E)(0800)(0020)(0000)
In this dump, the four-digit numbers in parentheses are abbreviations for "IP address" records, showing only the blocking mask part. We had already figured out, although it's a break with the tradition set elsewhere in the file, that in the six-byte IP address records, the blocking mask comes at the end instead of the start. Not shown in this dump is the enormous variability in the number of IP addresses apparently associated to each "length byte record"; some had dozens, many had none at all.
Also, although it looks okay in this fragment, there's a critical problem of how to recognize which records are which. The dumping program would guess what looked like a plausible IP address, but it sometimes guessed wrong and produced junk until it happened to randomly re-synchronize. It appeared that IP records with a blocking mask of 0x0000 helped signal "OK, length byte records coming now", and a length byte of 0x00 (not shown here) signalled the start of a list of IP address records, but these things raised problems because it appeared that in a list of IP addresses, there would always be one more address than there were blocking masks. Where would the blocking mask for the last IP address come from?
Late one night, under the influence of a couple bowls of MSG-saturated Korean instant noodles ("kimchee" flavour), we realised what we should have seen all along. The "IP address" records are actually the major records, and the other records go inside them, as children of a parent IP address. This makes more logical sense, given the purpose of the file; the package blocks either an entire IP address, or one or more subsections of an IP address. Then the rest of the structure fell out easily.
The basic record contains an IP address and a blocking mask. If the blocking mask is nonzero, it applies to that entire IP address. If the blocking mask is zero, then there are a number of subrecords, each consisting of a length byte, a blocking mask, and one or more four-byte unknown fields. A length byte of 0x00 terminates the list of subrecords and signals a new IP address.
Now, what about those subrecords? Well, they obviously represent some kind of subdivision of an IP address - like, for instance, a directory full of Web pages. Here's an entry from table 1, decoded by a more sophisticated Perl program that also incorporated reverse lookups of the IP addresses:
207.34.139.253 (pii300.bc1.com):
000E D2A152F4 23AC865E
0002 D2A152F4 9ECA24AB
000E D2A152F4 4337DDA1
001E D2A152F4 F1909EA3
000E D2A152F4 8532C8E2
This particular entry stood out partly because bc1.com is an ISP local to one of us. We have friends with pages on that system (although not, as far as we could tell, at the particular URLs blocked by Cyber Patrol). It also stood out because all the subrecords start with the same four-byte sequence. That's a pattern that appears in lots of other entries, too; there will often be a site where several subrecords start with the same four-byte sequence. Here's a good example (it's long, so we've left out part):
158.43.192.14 (twister.dial.pipex.net): [...] 000E 86AC9240 000E 4603712B 0002 D7E769CA 001E 0B01848F 000E 8A1266F1 000E 6DA218B8 957FF449 607AB5ED 000E 6DA218B8 957FF449 E90B0308 000E 6DA218B8 957FF449 D5D0798C 0002 6DA218B8 6A96D698 5F78E699 000E 6DA218B8 6A96D698 CCA4ED77 000E 6DA218B8 118AA2D3 5B69B41C 000E 6DA218B8 3CEC7FA9 48E41B10 000E 6DA218B8 3CEC7FA9 09ED716A 001E 6DA218B8 9B826D61 9BEC198D 000E 6DA218B8 9B826D61 8EF51A8C 000E 6DA218B8 1A7E65EE 8E16AE15
Notice how the four-byte values seem to be grouped together in an hierarchical structure. Just like directories... It seemed a reasonable guess that in fact, that's what they were. If they wanted to block a URL like http://www.foo.com/bar/baz/, maybe they'd do it by creating a record with the IP address of www.foo.com, and a subrecord with some representation of the strings "bar" and "baz".
We said "some representation of the strings". What, exactly, does that mean? Well, it would be quite reasonable to suppose that these four-byte fields are hashes, similar in nature to the password hashes. They could feed each URL component into a hash function, store only the hashes, and then have enhanced security as well as various efficiency advantages.
We figured out the exact nature of the hash function with the aid of the bc1.com entry. As you can see above, every subrecord for that server starts with the hash value 0xD2A152F4. If you look on the corresponding Web site, you find that it's an ISP's server for user home pages, all of which are stored in a "users" subdirectory. And it just so happens that in the nonstandard CRC32 variant that was used as half of the HQ password hash, the hash of the string "users" is 0xD2A152F4. Problem solved. We've designated this structure TNotURLEntry.
Above we explain the cryptanalysis of CRC32 in considerable detail, and we show how to construct, in negligible time, an input that will generate any output of our choice. As with the passwords, Cyber Patrol doesn't use any salt for its URL hashes, so we can recognize where there are duplicate directory names even without reversing the hashes, and get extra value for each hash we reverse because the same reversal will be valid for all other occurrences of that hash.
Unfortunately, there is what might be called an "information theoretic" problem with reversing these hashes. There are many possible directory names that could generate the same CRC. We can never be absolutely sure which of several equivalent (same CRC) URLs was actually meant to be blocked. In the case of the HQ password, we could use the other half of the hash output to recognize which one was correct, but here, that doesn't work. In a perverse way, shortening the hash has actually increased its security. But one good thing for us as attackers is that of the many possible strings, only a few will be meaningful. Given the choice between "sex" and "dkbgl~3.a7df", few would argue with our choice of "sex". For the small number of hashes which are hashes of very short strings, we can guess that the short strings are really correct - there are so few possible strings of five or fewer characters, that they're almost certainly right.
But for most hash values, the CRC32 reversal isn't really very helpful. For any given hash it generates a long list of possibilities, most of which are garbage. Instead of sorting through them, we fell back on the old reliable dictionary attack. We took a list of words and hashed them all, and then started modifying them by tacking tildes onto the start (to make it look like user home directories), adding letters to the start and end, adding ".htm" and ".html" to the end, and so on.
The source file "cndecode.c" implements this attack on the cyber.not file, as well as incorporating decryption code, some prettier output formatting, and (for systems where this works) reverse DNS lookups. It uses a hash table, and remembers the reversal of each hash for use on future occurrences of that hash, in an effort to be as efficient as is reasonable, although the prime emphasis was on expediency in programming over squeezing out the last CPU cycles.
As a last resort, if it can't find a hash in the dictionary, the cndecode program goes through all the possible reverse-CRC values up to a configurable limit, assigning scores to them based on how plausible they seem, and then chooses the best. That takes a relatively long time (significant fraction of a second) per hash, and it doesn't really work very well, but it does catch a few that aren't caught by the dictionary attack. Here's a sample of the output:
************************************************************************ www1.iastate.edu = 129.186.1.22 0006 http://129.186.1.21/.wmdnl/ 000E http://129.186.1.21/~blak/ 0008 http://129.186.1.21/~cwhipple/ 0820 http://129.186.1.21/~ejackson/ 0010 http://129.186.1.21/~ipdpfid/ 0001 http://129.186.1.21/2kihan/ 000E http://129.186.1.21/~omega/ 0008 http://129.186.1.21/~roymeo/ 0800 http://129.186.1.21/s(ettk/ 0001 http://129.186.1.21/~thinker/ 0001: Violence / Profanity 0006: Partial Nudity, Full Nudity 0008: Sexual Acts / Text 000E: Partial Nudity, Full Nudity, Sexual Acts / Text 0010: Gross Depictions / Text 0800: Alcohol & Tobacco 0820: Intolerance, Alcohol & Tobacco ************************************************************************
As this shows, URLs tend to be sorted within a given IP address. The ones that aren't in sorted order are probably ones for which the reverse-CRC didn't guess the right reversal. A more sophisticated version might attempt to detect the sorted order, and force the reverse-CRC to choose a reversal which would fit into the sorted order, but the amount of work involved would probably be more than it's worth.
This entry also shows something else we haven't talked about yet - "alias" IP addresses, which are the apparent purpose of the one remaining table in cyber.not. The structure can be seen in the TNotIPEntry. These aliases are just that. Each entry consists of a root IP and one or more aliases to that one. The root IP corresponds to entries in the URL table, and any resource banned under the root IP will also be banned under its aliases. These aliases may or may not resolve to the same machine; the assumption here is that these IPs are serving the same pages.
Let's talk briefly about hash collisions. The chance that any two randomly chosen URL components will happen to have the same hash is one in 2**32, which is not very likely. This is true even with the uneven distribution of URLs, because CRC32 is a reasonably good hash just as a hash, for all its cryptographic weakness. So at first glance, it doesn't seem like there'll be a big problem of different URLs having the same hash.
But the birthday paradox comes into play, too. With 2**32 possible hash values, there starts to be a serious chance of collisions as soon as the number of hashes gets past 2**16, which is 65536. It's certainly easy to imagine that a large ISP could have more than that many user home pages at the same location in their URL tree. Then two or more different sites would have the same URL as far as Cyber Patrol is concerned, and any block on one such page would hit the others. Given the current size of the Net and the size of cyber.not, there probably aren't any real examples of this kind of problem in the cyber.not file. But there is very little safety margin. A 64-bit hash would remove any suggestion of collision risks, at the cost of a considerable increase in filesize.
Of course, using a 64-bit hash would improve our ability to attack the cyber.not file too, by reducing the number of possible URLs for each hash value. Remember how having the second half of the HQ password hash made it so much easier to unambiguously reverse the hash? Information theory makes this tradeoff unavoidable: the fewer possible collisions, the easier and more unambiguous dictionary attacks will necessarily become. Given that bytes in cyber.not are somewhat expensive (because the file has to be transferred to all the users in updates all the time), the choice of a 32-bit hash is probably reasonable, even though it has some small risk of creating false blocks.
A more practical security measure would be to salt the URL hash. In the section on the HQ password we described how salting that hash would make dictionary attacks on the password much harder. With the URL hashes that becomes all the more significant, because with the URL hashes we aren't attacking just one hash value. We're attacking a few tens of thousands of hash values all at once. So anywhere we can recognize that two hashes are the same, that's a win, and any time we hash a dictionary word, we can easily check it against all the hash values in cyber.not all at once.
If every URL in cyber.not had been hashed with a different salt value, then we would have to hash an entire dictionary for every URL instead of just hashing one dictionary for the entire file. That would raise our time for a dictionary attack from a few CPU minutes to a few CPU months - we could still do it, possibly by recruiting a network of volunteers to compute cooperatively, but not as easily as the present attacks.
They wouldn't even need to make cyber.not any bigger to get the benefit of salted hashing - they could just use the offset of each URL in the cyber.not file as its salt value. Salt doesn't have to be random or secret, it just has to be different for each hash. They would also have to upgrade the hash function to one that isn't linear like CRC32; with CRC32, we could simply figure out the hash of the salt, XOR it out, and then have an unsalted hash to attack normally. A much more secure approach, which wouldn't make cyber.not any bigger, would be to take the offset and the URL, hash them together with SHA1, and then take the bottom 32 bits of the result.
But even that wouldn't raise the difficulty of attack above the level of competent amateurs, and indeed, there is no way to make this kind of hashing scheme any more secure. There just aren't enough possible URLs on the Web; it's too easy for attackers to guess all possible URLs and test them to see which ones would be blocked. Unix sysadmins accept the fact that attackers can test passwords offline, and attempt to educate their users to choose hard-to-guess passwords, but censorware companies cannot ask all objectionable Web sites to choose hard-to-guess URLs. So they ultimately cannot defend themselves against this form of attack. With salt in the hashes, though, they could make it a lot harder for us.
Next, the cyber.yes file contains "positive option" URLs; when the software is configured to its strictest setting, only these URLs will be permitted. There is also a list of newsgroups at the end that seems to be in identical format to the one in cyber.not. A quick scan of the decrypted file with a text lister showed that it's full of fragments of ASCII text, like this (dump generated, amusingly enough, by Richard E. Morris's good old DOS-based HEXEDIT program):
000880: 0B 01 00 7E 63 68 69 6E 6F 6F 6B 00 81 80 3D 11 |...~chinook...=.| 000890: 00 00 06 08 00 77 73 69 00 81 80 44 0A 00 00 15 |.....wsi...D....| 0008A0: 10 00 7E 77 61 6E 69 67 61 72 2F 73 70 61 63 65 |..~wanigar/space| 0008B0: 6C 69 6E 6B 00 81 0D 0A 64 00 00 10 09 00 7E 74 |link....d.....~t| 0008C0: 68 67 72 69 65 73 2F 64 69 73 63 00 81 89 C2 89 |hgries/disc.....| 0008D0: 00 02 81 89 21 25 02 40 81 0F 02 5A 00 00 07 40 |....!%.@...Z...@| 0008E0: 00 6F 75 70 64 19 48 00 7E 6E 77 73 2F 73 70 6F |.oupd.H.~nws/spo| 0008F0: 74 74 65 72 67 75 69 64 65 2E 68 74 6D 6C 00 81 |tterguide.html..| 000900: A4 28 6C 10 02 81 A4 28 DF 80 00 81 A4 28 E1 10 |.(l....(.....(..| 000910: 82 81 B1 0C 0C 00 00 0F 40 02 70 65 6F 70 6C 65 |........@.people|
These look like URL fragments, but they also look sort of haphazard. In fact we theorized at one point that they might be stray garbage from memory allocation calls. However, they do have a purpose, and once we had the format of the cyber.not file, the cyber.yes file became easy to figure out.
The same correlation-counting program that we ran on cyber.not showed similar results on cyber.yes, with strong correlation at a distance of six characters, but unlike cyber.not, no sharp peak at seven characters. This suggested that the format for the main table in cyber.yes would be very similar to that of cyber.not. Examination of the hex dump showed similar stretches of six-byte repeats with a field incrementing in big endian.
A little trial and error revealed that the format is essentially identical: records with IP addresses and two-byte "mask-like" fields. We say mask-like because it's not clear that they serve the same function as the mask fields in cyber.not. When the mask-like field is zero, there follows some number of variable-length URL records, terminated by a zero byte. There are two significant differences in the subrecord format. First, the URL is in plain text instead of being hashed. As a result, the variable length can assume a less restricted set of values. Second, the "mask" field appears to have a different significance. Here is a sample record from cyber.yes:
202.231.128.32: 0802 "home/dbec1" 5A8A "home/kazoo" 5A8A "home/kiboc" 5A8A "home/kimin" 5A8A "home/sanyohs" 7ACA "home/terada" 7AEA "home/tomoy" 7AEA "home/tomoyuki" 7BFA "home/ueno" 7BFA "home/warp"
The hexadecimal column is the field that in cyber.not would be the blocking mask. Here, it's not clear what it is. It could be some kind of anti-blocking mask, of categories NOT to block, but then it's surprising that it would be in sorted order (a pattern that persists in other records too), especially when the URLs are also in alphabetical sorted order. Other possibilities for this field include some kind of time stamp, a serial number, an index pointer, an authentication token or hash, or random memory garbage. The "mask-like" fields on IP addresses similarly show little apparent design, except that (just as in cyber.not) a zero value indicates the presence of URL subrecords. The newsgroup list has mask-like fields too, and there's no immediately obvious meaning to the data in them.
At this point we should note the overall file structure of cyber.yes. Unlike cyber.not which had an elaborate header, the header on cyber.yes consists of just three bytes: one version number (or possibly encryption key fixup), and two bytes giving the length of the URL table. We discovered this by working backwards from the URL table until we found that all the bytes in the file except the first three made sense as part of the URL table. The newsgroup list follows immediately after the URL table and continues until the end of the file, in the same format as the cyber.not newsgroup list except with unknown data where the blocking mask would go. Unlike the tables in cyber.not, both tables in cyber.yes are just bare data, with no "SD" and "ED" delimiters.
This file structure is interesting because it seems stripped down or simplified from the structure of cyber.not. It would be reasonable to guess that the cyber.yes format was a quick hack retrofitted onto the product subsequent to the more carefully-designed cyber.not table. It's also possible that the cyber.not format proved too complicated and cyber.yes is an example of a "leaner and meaner" file format, still keeping to the same design principles as cyber.not and likely re-using a lot of code originally written for cyber.not.
Following are the relevant structure tables. This concludes the section on reversing the file formats.
| TNotHeader | ||
|---|---|---|
| Offset | Size | Description |
| 0x0000 | 2 | Filetype? (0x00FC) |
| 0x0002 | 2 | Header size (0x002A) |
| 0x0004 | 2 | Header id ('CH' or 'HH') |
| 0x0006 | 2 | unknown ( 00 00 ) |
| 0x0008 | 2 | unknown ( 00 00 ) |
| 0x000A | 2 | unknown ( 03 01 ) |
| 0x000C | 2 | Count of TNotHeaderEntries (0x0003) |
Immediately followed by one or more of these:
| TNotHeaderEntry | ||
|---|---|---|
| Offset | Size | Description |
| 0x0000 | 2 | Table type ( 4x 00) |
| 0x0002 | 4 | Absolute offset |
| 0x0006 | 4 | Size (in bytes) |
The problem here is the Table Type field which we have too little data to fill in with any certainty. We can build the following table from the files we have analysed so far, built around the types that have occurred and the type of data they pointed to.
| TNotTableType | ||
|---|---|---|
| Value | Binary | Description |
| 0x0041 | 0100 0001 | Points to TNotIPEntries in cyber.not |
| 0x0047 | 0100 0111 | Points to TNotNewsEntries in hotlist.not |
| 0x0049 | 0100 1001 | Points to TNotURLEntries in cyber.not and hotlist.not |
| 0x004E | 0100 1110 | Points to TNotNewsEntries in cyber.not and hotlist.not |
| 0x004F | 0100 1111 | Points to TNotURLEntries in hotlist.not |
We can make no detailed conclusions from so little data.
| TNotIPEntry | ||
|---|---|---|
| Offset | Size | Description |
| 0x0000 | 4 | IP |
| 0x0004 | 1 | Count of additional IP addresses (typically 1-23) |
| 0x0005 | * | IP x count |
| TNotURLEntry | ||
|---|---|---|
| Offset | Size | Description |
| 0x0000 | 4 | IP Address |
| 0x0004 | 2 | Category blocking mask or 0x0000 to indicate a subrecord follows |
| Subrecord | ||
| 0x0000 | 1 | Subrecord size |
| 0x0001 | 2 | Category blocking mask |
| 0x0003 | * | URL hash |
In the case where there are one or more subrecords, the list is terminated by a zero byte.
| TNotNewsEntry | ||
|---|---|---|
| Offset | Size | Description |
| 0x0000 | 1 | Record size |
| 0x0001 | 2 | Category blocking mask |
| 0x0003 | * | Newsgroup string |
Now, for the cyber.yes:
| TYesHeader | ||
|---|---|---|
| Offset | Size | Description |
| 0x0000 | 1 | Filetype? (0xFB) |
| 0x0001 | 2 | Count of TYesURLEntries |
This is the only record-type of the cyber.yes:
| TYesURLEntry | ||
|---|---|---|
| Offset | Size | Description |
| 0x0000 | 4 | IP Address |
| 0x0004 | 2 | Unknown, or 0x0000 to indicate a subrecord follows |
| Subrecord | ||
| 0x0000 | 1 | Subrecord size |
| 0x0001 | 2 | Unknown |
| 0x0003 | * | URL as plaintext |
Same as for the TNotURL-entries, in the case where there are one or more subrecords, the list is terminated by a zero byte.
With all these technical things resolved, let's look at the data itself. First a table of statistics pulled from two different CyberNOT files:
| Cyber Patrol URL Database Statistics | ||||
|---|---|---|---|---|
| Bit | Category | 1999-04-29 | 2000-02-20 | Change |
| 0 | Violence / Profanity | 1201 | 1407 | +206 (17%) |
| 1 | Partial Nudity | 46538 | 72236 | +25698 (55%) |
| 2 | Full Nudity | 45013 | 70248 | +25235 (56%) |
| 3 | Sexual Acts / Text | 47769 | 74009 | +26240 (54%) |
| 4 | Gross Depictions / Text | 1414 | 2273 | +859 (61%) |
| 5 | Intolerance | 259 | 337 | +78 (30%) |
| 6 | Satanic or Cult | 129 | 197 | +68 (53%) |
| 7 | Drugs / Drug Culture | 197 | 306 | +109 (55%) |
| 8 | Militant / Extremist | 187 | 204 | +17 (9%) |
| 9 | Sex Education | 201 | 270 | +69 (34%) |
| A | Questionable / Illegal & Gambling | 1347 | 1928 | +581 (43%) |
| B | Alcohol & Tobacco | 783 | 1155 | +372 (48%) |
| C | Reserved 4 | 48 | 3 | -45 (1500%) |
| D | Reserved 3 | 0 | 0 | 0 (0%) |
| E | Reserved 2 | 0 | 0 | 0 (0%) |
| F | Reserved 1 | 0 | 0 | 0 (0%) |
| Total URL masks | 52315 | 79899 | 27584 (52%) | |
We can see that of the roughly 80000, entries about 90% fall into one or more of the pornography categories. The Learning Company have a page on their site describing their criteria for categorizing entries. At the end it states: "Note: Web sites which post "Adult Only" warning banners advising that minors are not allowed to access material on the site are automatically added to the CyberNOT list in their appropriate category.". This may give the impression that sites are automagically added as soon as they appear on the web, which certainly isn't the case. They are most probably using a web spider to pick these up. These spidered sites probably make up the bulk of the URLs flagged in all of categories 1, 2 and 3, which is the dominant set of flags by far. By monitoring these statistics for a longer period of time one could deduce how effective the spider is in finding new sites. The oldest cyber.not we have available is dated 1999-04-29. By comparison it contains only 52315 entries, but the ratio of "porn" rated sites is the same, about 89%, with 46538, 45013 and 47769 entries flagged for categories one, two and three respectively. Most of the other categories are up by between a hundred and three hundred entries, but the porn categories, suspected mostly to consist of spidered sites, are up by about 25000 entries each for the period (about 38 weeks).
There is a function in CP where a user can use a form to report new URLs for consideration of inclusion into the CyberNOT. It would be interesting to know how many of the URLs added come in this way. It would be possible for users to team up and exchange URLs on their own, bypassing The Learning Company, which is charging for these CyberNOT updates. By patching the CP executable it could be made so that this report form is posted to another server, which could also host updated CyberNOT lists. It would take a little work to set up, but not too much. The most difficult aspect would probably be to reach out to active Cyber Patrol users and convince them that this would be worthwhile, especially since it would require a certain amount of momentum to be worthwhile at all. With this threat, it's logical to assume that The Learning Company and other censorware vendors will use even more security-through-obscurity in future products, to deter the threat of having one of their sources of income bypassed.
Near the start of this essay we mentioned the "reserved" blocking categories. Cyber Patrol, in addition to the twelve documented blocking categories, has an additional four (labelled "Reserved 1" through "Reserved 4") which are greyed out. Reserved 3 and Reserved 4 are selected by default, and so cannot be disabled - even by the administrator.
Any sites placed in one of those two categories will be blocked no matter what. We found three examples on the now current CyberNOT list. All three are in Japanese. They were each blocked in Reserved 4 and no other categories; we could not find any examples of blocks on other reserved categories.
There are a few entries in the CyberNOT list that are blocked under all non-reserved categories. For instance, the anti-censorware site of Peacefire is listed as containing "Violence / Profanity, Partial Nudity, Full Nudity, Sexual Acts / Text, Gross Depictions / Text, Intolerance, Satanic or Cult, Drugs / Drug Culture, Militant / Extremist, Sex Education, Questionable / Illegal & Gambling, Alcohol & Tobacco". That's not such a surprise; blocking Peacefire has become traditional among censorware manufacturers.
The other sites blocked under all categories seem to be translation and anonymizer services; any site where you can type in a URL and it will present you a copy of that page. That's probably no big surprise either, because such sites can be used to circumvent censorware. So it may be reasonable that sites like anonymizer.com should be blocked under all categories; potentially, they do make available the entire range of human thought. Not all these blocks are carefully applied, however; the "STOP KITTY PORN" page (which features a picture of a very bored-looking house cat) is blocked under all categories apparently just for containing a link to anonymizer.com. Here, as elsewhere, the blocking list doesn't seem to be updated very frequently. The server at 207.55.200.2 (whose reverse-DNS resolves to "www.live4u.com", although that doesn't resolve in the forward direction) seems to be an ordinary portal site, with no obvious translation service, but it's blocked for everything except sex education.
Of course, the most interesting things we could find on the blocking list would be sites about political or social issues. Other censorware packages have gotten in a lot of trouble, for instance, by blocking sites like the National Organization of Women, and a great many gay and lesbian sites. The CyberNOT list seems relatively free of that kind of political agenda, which could be a good or a bad thing depending on your point of view. If the software is to be installed in public libraries, it's good that it won't block these politically-important sites. Of course, it would be better if it didn't block any sites at all. On the other hand, if you were a parent who considered feminism or homosexuality to be unimaginably horrid subjects, then you might feel ripped off by Cyber Patrol's not blocking the high-profile sites.
Let's take a closer look at the category intolerance. While they do block smaller sites, such as this one on atheism, which we feel is relatively benign, they also block such high profile a site as www.godhatesfags.com and part of American Family Organization, whose views on homosexuality cannot be described as anything if not intolerant. AFA is one organization pushing for the installation of censorwares in US libraries. One can only assume they'd prefer one of Cyber Patrol's competitors.
Some other sites in this category:
How very intolerant of them to be working for free speech, huh?The Justice on Campus Project's mission is to preserve free expression and due process rights at universities. Our online archive includes reports on disciplinary charges, speech codes, and censorship on college campuses around the country. The Project was one of 20 plaintiffs in the ACLU's successful challenge of the Communications Decency Act.
How about some examples from the category "Satanic / Cults"?
There is one political issue the CyberNOT list doesn't shy away from: that of nuclear disarmament. All sites relating in any way to war, bombs, explosives, or fireworks, both for and against, seem to be eligible for blocking as "Militant / Extremist". Most are also classed as "Violence / Profanity" and "Questionable / Illegal & Gambling", whether those categories seem to apply or not. For instance:
Is that an extremist position?Founded in 1981, the Nuclear Control Institute (NCI) is an independent research and advocacy center specializing in problems of nuclear proliferation. Non-partisan and non-profit, we monitor nuclear activities worldwide and pursue strategies to halt the spread and reverse the growth of nuclear arms. No Bomb! In particular, we focus on the urgency of eliminating atom-bomb materials ---plutonium and highly enriched uranium---from civilian nuclear power and research programs.
Blocked as "Violence / Profanity, Militant / Extremist, Questionable / Illegal & Gambling".Nazism, fascism and extreme nationalism are today at its highest peak since the destruction of Hitler's dictatorship in 1945. Today, all over the world, fascists and extreme nationalists win millions of votes on their simple racist solutions to very complex problems of the society. In the streets, Nazi boneheads are spreading fear by using murderous violence and terror. These fascist groups blame the cultural and ethnic minorities for the problems in our society. These individuals, and their political leaders, are a threat to our democracy, and to everything that is decent.
Some sites that may be blockable under a few categories are also blocked under a great many other categories. For instance:
You go, boy.In school they teach me about this thing called the Constitution but I guess the teachers must have been lying because this new law the Communications Decency Act totally defys [sic] all that the Constitution was. Fight the system, take the power back, WAKE UP!!!!!
It is obvious on examining the list that many entries haven't been updated or checked in a long time. Many sites that are blocked now give 404 not found errors, or redirects to new locations that are not blocked. Changes to Web sites may also account for some of the inappropriate category labelling. Here are some samples of sites that seem inadequately reviewed:
These are just a few examples of sites that Cyber Patrol is banning, or was. It is not unthinkable that they might lift a few after this is published. We've only scratched the surface as far as checking on the sites that are banned. Going through even a few hundred takes a lot of time, and with almost 80,000 bans in effect, the work required to check them all would be enormous. We don't have time to do it, but since The Learning Company is making money from the supposed correctness of the list, they ought to be able to find resources to check the list from time to time.
We know they are banning 80,000 or so URLs, but most censorware packages also have a database of words that are not allowed to exist in incoming pages, because it's the only way to really approach being effective in banning new pages on the ever evolving and growing Internet. Cyber Patrol doesn't do that, and so its IP and URL bans are its only real line of defence. If you can find a site that The Learning Company have not, then there's very little stopping you from browsing it. There is the function that can filter a site based on substrings in the URL itself, but that is it.
Cyber Patrol is actually fairly efficient in blocking sites if you don't know how to search effectively. If you simple search one of the major search-engines then you will probably draw a blank, because it's very likely that that is the exact kind of search used by The Learning Company to bait their web-spiders. However, finding a few pages with obscene banners and thumbnail pictures is no big problem. We could locate this one and this one in short order. One somewhat effective method is to search for non-English language pages. The spider might not be effective in locating and parsing these for automatic inclusion in the CyberNOT. You could for instance look for a Swedish site, and locate www.smygis.com, which is not - as this is written - blocked in any way. If you really want porn, Cyber Patrol might slow you down a little, but it won't cut you off entirely.
Apart from checking for "unauthorized" modifications to cyberp.ini, CP's "advanced anti-hacker security" consists of a new %windir%\system\system.drv that checks for the existence of the modules PROGIC, PROGICS and TS. These are represented by the files IC.EXE, ICFIRE.EXE and TS.DLL, all in the %windir%. The original system.drv is cleverly hidden away as %windir%\system.386.
The modules are loaded in two ways: first there is a load entry in the win.ini file, and second, there's a entry in the registry at HKCU\Software\Microsoft\Windows\CurrentVersion\Run called "FltProcess", which will load %windir%\system\msinet.exe, which in turn will load the Cyber Patrol modules. After replacing the system.drv, which in the CP-version will halt loading of Windows if it doesn't find it's modules, and ask you to call their support number, you can safely do away with the registry entry, the load-key in the win.ini and any of the numerous binaries. Because of the many files CP installs to your system, we suggest you use the normal uninstaller instead. Not that it does a very good job of removing its system files, but there you go.
Optionally, if you come across an installation running unregistered, you can use the backdoor password omed to uninstall, or simply to gain administrator access.
We have developed a set of software for getting around Cyber Patrol. People oppressed by Cyber Patrol will want to take a look at CPHack, a Win32 binary which will decode the userlist for you, and also let you browse the different banlists.
Also available is C source for two command-line programs illustrating the cryptographic attacks on cyber.not (cndecode.c) and the HQ password hash (cph1_rev.c). These programs were written under Linux and are not guaranteed to work anywhere else.
A complete package with this essay, the binaries, and various sources and related files are available as cp4break.zip (~360Kb).
This tool is not particularly hard to use, but some comment on its use could be in order. First of all the author would like to state that this is a hack(1), which is reflected both in the state of the source and the user interface. The basic functionality is to let you load and browse the information of a cyber patrol .not file and/or the user information contained in a cyberp.ini file. Simple select which you want to load using the file menu. Also in the file menu are functions for importing and exporting hosts. By importing hosts you are reading a text file containing lines of IPs and their corresponding hostnames into the treeviews. Export, of course, does the opposite.
Continuing we have the functions "Export dictionary" which will traverse the treeviews and write out all words that have been assigned to URL-hashes. "Export unresolved IPs" does just that; it could be used to distribute the work of doing reverse-lookups. The final export function is "Export URL hashes", which will export any hash that has not been assigned a word, the logical inverse of the "Export dictionary" function.
Maybe the most useful functions are the last ones, "Generate report", which will output a HTML document reflecting the data you have loaded. Be sure to check out the "Configuration" tab before doing that though, and the somewhat mysterious "Cull dictionary by hash". The last function will take the main dictionary (as defined in the configuration tab), and create a new dictionary containing only the words with hashes contained in a .not file you have loaded. A bit of explanation on this: It was thought by the author that a lazy dictionary attack would be enough. This lazy approach is what you get if you select one of the attacks available by right-clicking a node. However, this proved quite slow when used with large dictionaries (15Mb or so), as it only looks at one URL at a time.
The problem here is that CPHack will try - for each node - lots of words from the dictionary with hashes that doesn't exist in the database at all. As a quick hack on the hack, this function was implemented, which will take all the hashes in the database and attack them all at once. The downside is that no references are kept as to which exact nodes the found hashes belong to, so you will only get a new optimized dictionary to use in the lazy attack, you won't get a instant update to the treeview. While desirable, it would take too much time and effort - at this point - to implement correctly. A good implementation would traverse the nodes you have selected, creating a ordered list of unique hashes, attached to which would be lists of all associated nodes. When the hash of a word is found in this ordered list of hashes, the correct chain of tree nodes could be quickly traversed and nodes updated to reflect the hit. Until this is fixed, you should cull the dictionary first, and use the output with the lazy attack, to "assign" all words into the database.
The main interface contains the five sections "Users", "Newsgroups", "URL database", "IP Aliasing" and "Configuration". A quick rundown follows.
If you load a cyberp.ini the "Users" tab will display the names and passwords of the users therein, including the passwords of the innate administrator and deputy accounts.
After loading a CyberNOT file, the "Newsgroups" tab will display all filters defined therein. To the rights is a panel of checkboxes which you cannot operate, but will reflect the masks applied to the newsgroup entry you select in the listview.
Next we have the "URL database" tab, which contains a treeview where you can browse the database. It should be noted that the relative long loading time of a CyberNOT file is due to the way the treeview works, with insertion into a branch - apparently - being O(n) and not about O(1) in regard to the number of siblings of a new node. Anyway, you can browse the view in the normal manner of things. There are three different types of nodes, the first being called internally a "net node". This is simply a root node containing all entries for IPs of a "A net". Below these are "IP nodes" which are the IPs that are banned by the database. Some of these have children of their own, being "URL nodes" which contains the hashes of specific paths and resources being banned. You can right-click on any one of these three types of nodes for additional context sensitive functionality, such as "Open", "Lookup" and "Dictionary attack". As with the newsgroups tab, there is a panel of checkboxes which will reflect the masking status of the IP or URL you select. At the bottom is a quick search bar where you can do case sensitive string searches.
There's not much to say about the "IP Aliasing" tab, but here too you can right-click for additional functionality.
Finally we have the configuration tab where you define the different dictionaries you want to use, and a number of other things which are self-explanatory, except maybe for the "Lock found URLs". This function, if enabled, makes sure that once a word has been found to match a hash and been attached to it in the treeview, then it will never get replaced even if another possible candidate is found.
This program is entirely self contained. It will not write to the registry, and it will not create files anywhere but in the its own path, unless you say it can.
The source is included, and you can do whatever you want with it.
On the good side, we note that Cyber Patrol is - technically - somewhat better than NetNanny and CyberSitter, the two other censorware packages we have intimate knowledge of, but there is still far too much 16-bit code for it to be really stable and earn a good grade.
We see no evidence of a clear political or religious agenda behind Cyber Patrol, though as citizens of highly secularized countries we might feel that many of the bans in the "Satanist / Cult" category are unreasonable. Their criteria document says "Satanic material is defined as: Pictures or text advocating devil worship, an affinity for evil, or wickedness." and "A cult is defined as: A closed society [...] Common elements may include: [...] influences that tend to compromise the personal exercise of free will and critical thinking." LaVey Satanism - for instance - isn't about any of the things in the full definition, and atheism certainly isn't, but such sites are included in the CyberNOT.
The evidence points to the CyberNOT list not being properly updated to remove old and outdated entries. As many as 50% of the IPs in the list doesn't even resolve! When evaluating a product with a ban list, you should not look at the number of entries, but the number of current entries. Simply collecting new entries, and using the ever growing (but outdated) list of bans as an argument in the sales game, is much easier than actually putting in work to ensure the list is up to date and accurate.
The old classic tactic of entering critics into the banlist continues, with the banning of Peacefire in almost every category available. When the producers are knowingly banning a site in clearly the wrong categories, then what kind of trust can you put in them and their products? None. We must continue to reverse-engineer these products so that consumer rights can be protected. Will we ever find a censorware company who are not lying to us with these false bans?
The absence of filtering based on content keywords is surprising, but welcome. The technology does not exist to make content-based filtering really functional. The problem of recognizing content and making choices based on context is a hard one, suitable for research by the AI-labs. But it is a two-edged sword. The price of leaving this error-prone functionality out is that it makes Cyber Patrol less effective in blocking pages not previously processed by The Learning Company.
After all this, the feeling is that CP is just another censorware package. It tries hard to come across as effective - the magical technical solution to a non-technical problem - but when push comes to shove, it yields to the power of the human mind. If you thought putting this between your children and the Internet would protect them from "dangerous" ideas, then you'd better think again.
We would like to thank all the fine men and women working for civil liberties all over the world.
Matthew would like to thank: the goddess Pele for favours received, and the Canadian government for supporting my cryptographic interests in several ways. Greetings to all the people I hang out with in sci.crypt, alt.kids-talk, talk.bizarre, and the VLUG and Voynich mailing lists.
Eddy would like to thank: Robert Risberg, Kristoffer Andergrim, Mattias Aspman, Gunnar Rettne, and all of my friends around the world. Special regards to all the intelligent, knowledgeable and humorous folks of R20 of the Fidonet - you know who you are.
All cryptanalysis done by Matthew Skala. Reverse Engineering done by Eddy L O Jansson and Matthew Skala. Feel free to contact the authors with your comments and/or questions.
This essay first published at Eddy's homepage in 2000-03-11. You'll find Matthew's homepage here.
You are allowed to mirror this document and the related files anywhere you see fit.
[DFR98] Saruman and Bobban, "The Penetration of CyberSitter'97", Apr 1998.
[DFR99] Saruman, "The Reversal of NetNanny", Aug 1999.
[ACLU96] American Civil Liberties Union "FCC V. Pacifica Foundation", 1996.
[RNW93] Ross N. Williams "A painless guide to CRC error detection algorithms", Aug 1993.
[JRG00] Raphael Finkel, Eric S. Raymond, et al. "The on-line hacker Jargon File, version 4.2.0", Jan 2000.
(c)2000 Eddy L O Jansson and Matthew Skala. All rights reserved. All trademarks acknowledged.
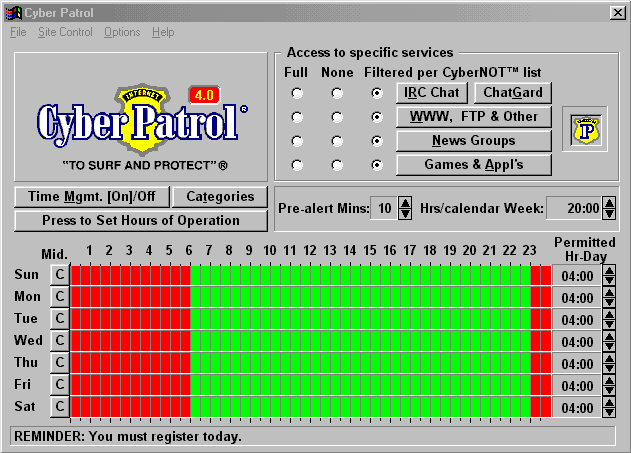{kind=link}
{kind=link}